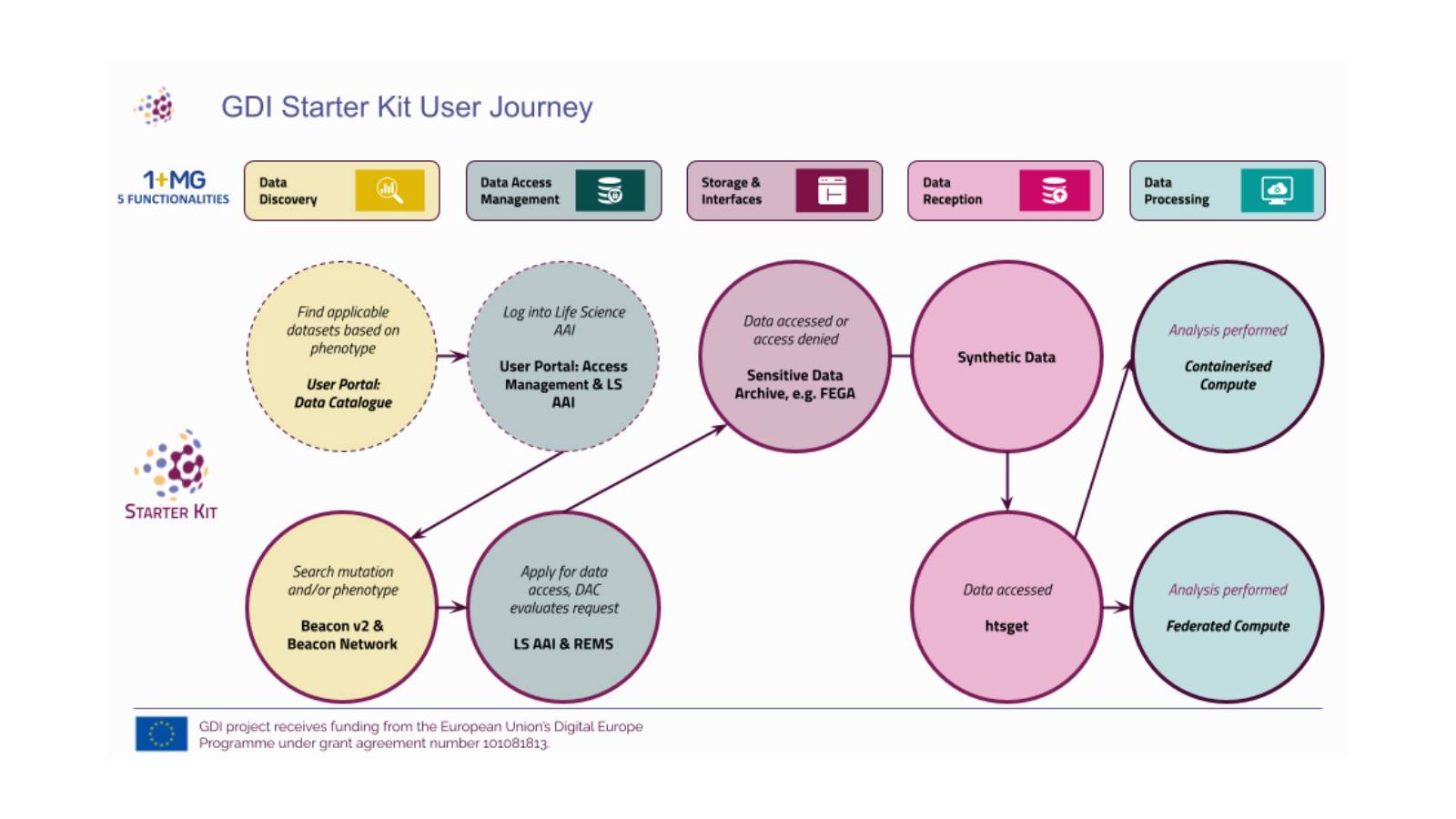
The GDI Starter Kit is a key project output that supports federated data access workflows. It will benefit not only the national nodes of GDI, but also in future public institutions and companies who can use the software technologies to increase legal, organisational, semantic and service interoperability by including these software and standards into their own environment.
The Starter Kit is a set of software applications and components co-developed by the 20 GDI nodes, based on open community standards from the Global Alliance for Genomics and Health (GA4GH). These have been tailored for new nodes in GDI to deploy during their onboarding phase. The Starter Kit gives all countries the technical capability to access synthetic genomic and phenotypic data across borders.
The Starter Kit includes more than 2,500 synthetic genomics and phenotypic data (including cancer, rare diseases and population genomics) and enables nodes to rapidly deploy a functioning pilot system, as a first step towards a production infrastructure. The Starter Kit is freely available to any interested parties, for example, industry can use the Starter Kit to understand what the GDI project plans to deliver and design their products accordingly.
Products in the Starter Kit are shown in the image below, many of them are open source software products that are operated as services in national hubs. LifeScience AAI and Beacon Network are offered as a service at the European level operations for the national hubs.
Dylan Spalding, the co-lead of GDI Work Package 5, shared the development progress of the Starter Kit and its impact: ‘The development of the Starter Kit products have been led by the product owners from 4 different countries, including Czech Republic, Finland, Spain and Sweden. These products have been developed in collaboration with other projects, such as Federated EGA. This helps ensure technical interoperability of the Starter Kit with other genomic data sharing platforms and provides a demonstration of the standards proposed for use within GDI which links the different components or products together, with the aim of making the data as FAIR as possible.’
Serena Scollen, the GDI Project Coordinator and Head of ELIXIR Human Genomics and Translational Data team, spoke of the importance of the GDI Starter Kit: ‘The GDI Starter Kit has generated a lot of excitement as it lays the foundation for how countries can deploy infrastructure to become operational and integrated into the 1+MG infrastructure. Advances are already evident in all 20 countries. Technical developments are paramount at this stage of GDI to ensure we are on a path to provide the infrastructure to support the discovery, access, sharing and analysis of human genomics data and linked phenotypic/other data on a massive scale.’
This release is the first version of the Starter Kit, which will be further developed during the lifetime of the project following an iterative approach. The Starter Kit is accessible here: https://github.com/GenomicDataInfrastructure